Epstein Library
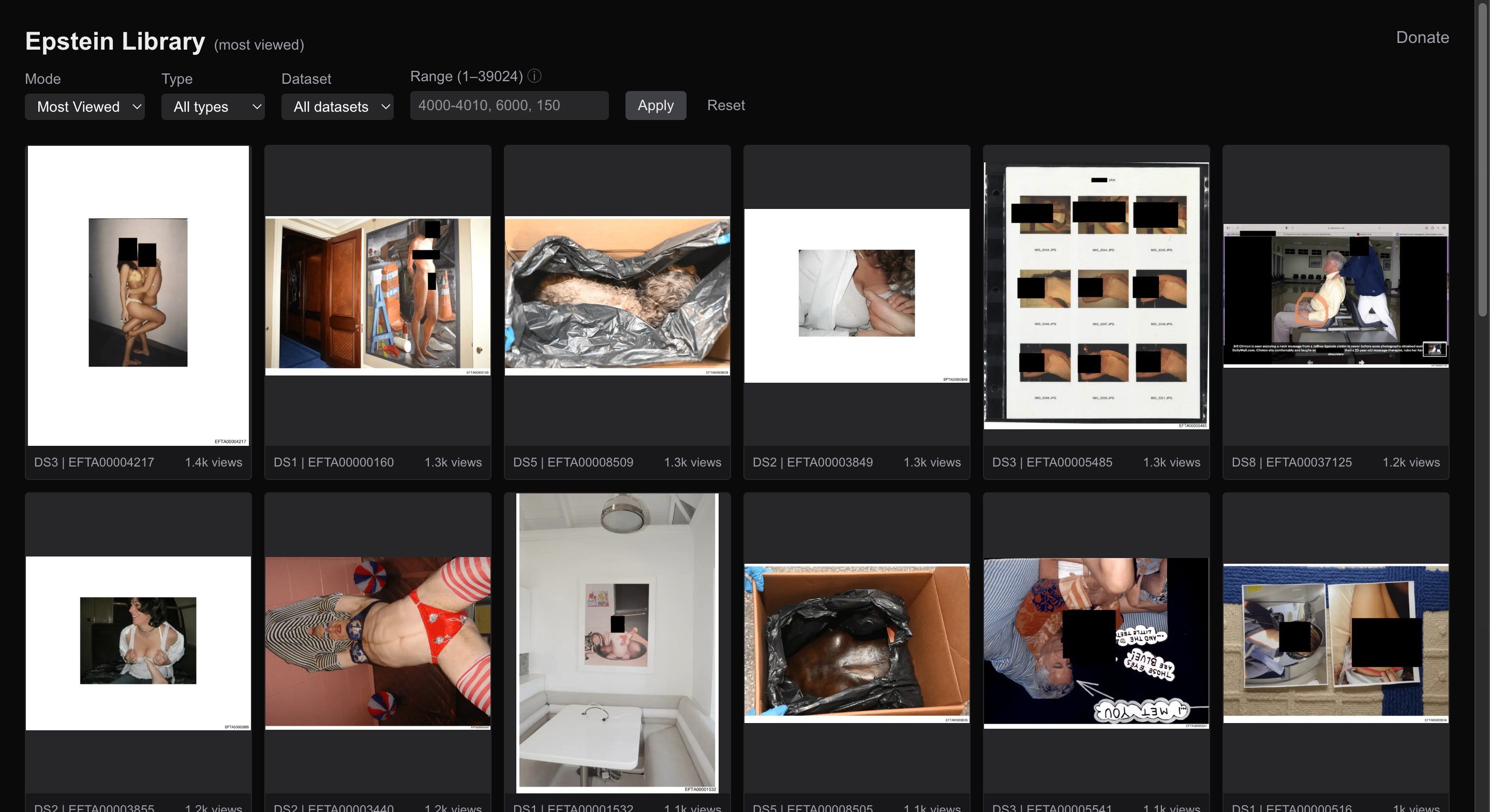
Vision
When the USA Department of Justice released the Epstein files in late 2025, I was immediately intrigued. I had followed the Epstein saga for years, and was fascinated with the dark world of Jeffrey Epstein, his connections, and the many mysteries surrounding his life and death.
However, I was disappointed that the files were just a massive dump of unorganized PDFs that were nearly impossible to sift through. I wanted to create a more user friendly way to explore the files, and thus the Epstein Library was born.
The Epstein Library is a web application that allows users to easily browse, search, and view the Epstein files in a more organized manner. Users can search by dataset, filter by file type, filter by most viewed, and view files in a clean and intuitive interface. The goal of the Epstein Library is to make the Epstein files more accessible to the public and to shed light on the dark world of Jeffrey Epstein.
After sharing the initial version of the Epstein Library on Reddit, it quickly gained traction and went viral, reaching over 150,000 views and 500+ upvotes. In 2 weeks, the website reached 11,000+ unique visitors. The response has been overwhelmingly positive, with many users praising the ease of use and organization of the files.
Check out the live website here.
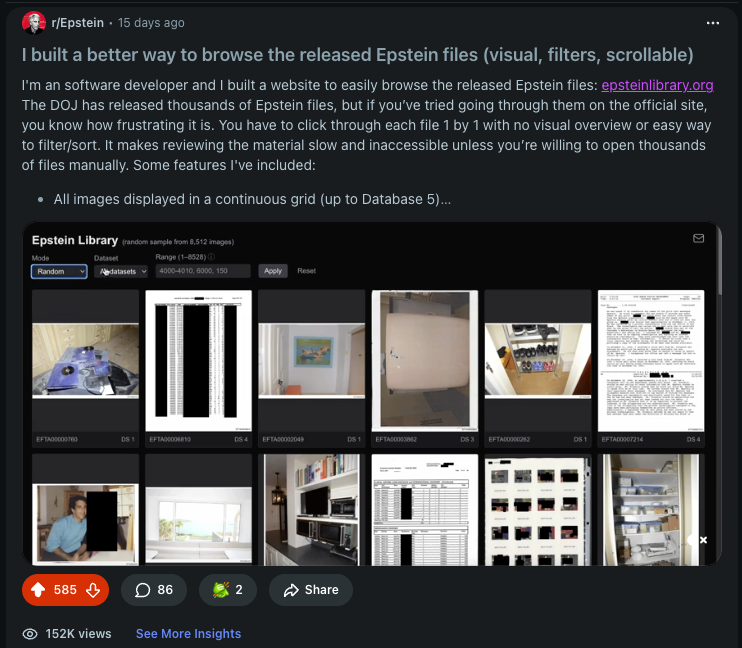
Initial Reddit post sharing Epstein Library, quickly going viral with 500+ upvotes and 150k+ views
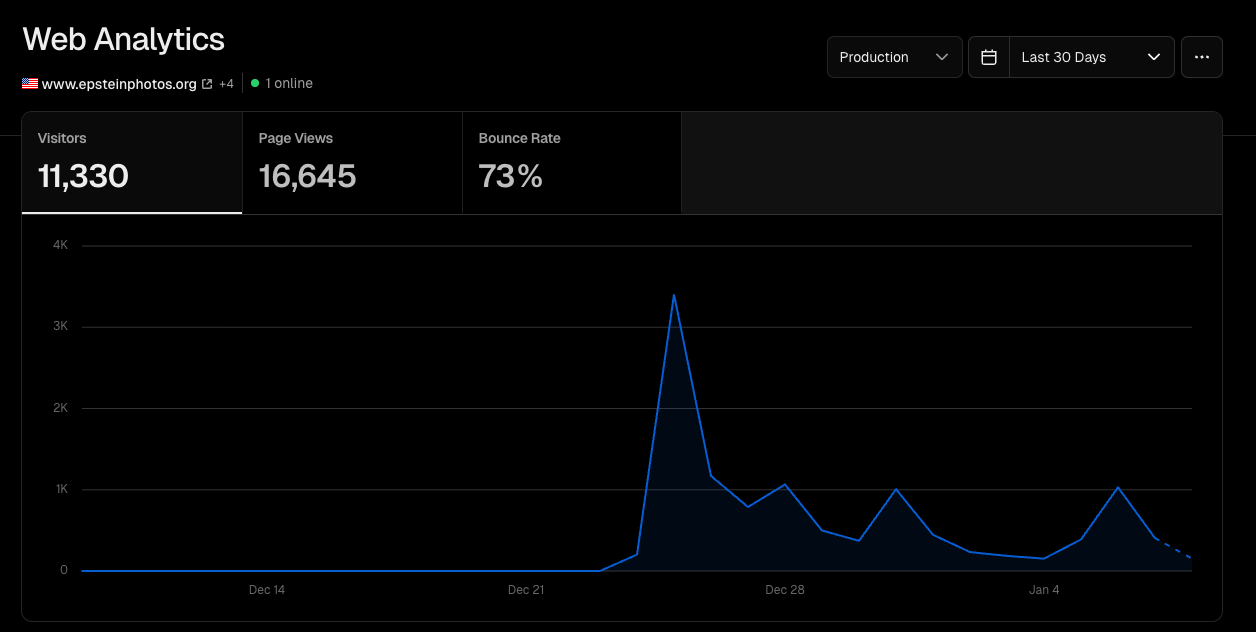
Reached 11k+ unique visitors and 16k+ page views in 2 weeks after going viral on Reddit.
Languages
- Typescript
- HTML
- CSS
- PostgreSQL
Dependencies
- Next.js
- Typescript
- Tailwind CSS
- Supabase
- Cloudflare R2
Features
EpsteinLibrary.org is a visual first archive designed to make large, unstructured document releases easier to explore and understand.
- Image-based browsing of released Epstein documents
- Fast, infinite scrolling gallery optimized for large datasets
- Search and filtering by dataset, file type, and popularity
- Ability to view random files and images or sort by ascending/descending file numbers
- Metadata-driven organization (DS numbers, EFTA numbers)
- View count tracking to surface the most accessed files
- Community tagging feature to add context and metadata for searchable images
- Mobile friendly viewing with swipe navigation
- Privacy first access with no account required
- Images are stored on Cloudflare R2 for fast, cost-efficient delivery at scale
- Metadata, view counts, and tags are managed in a PostgreSQL database via Supabase
- Optional donation links allow users to support hosting and infrastructure costs without restricting access

Zoom in modal view for easy reading and navigation between files.
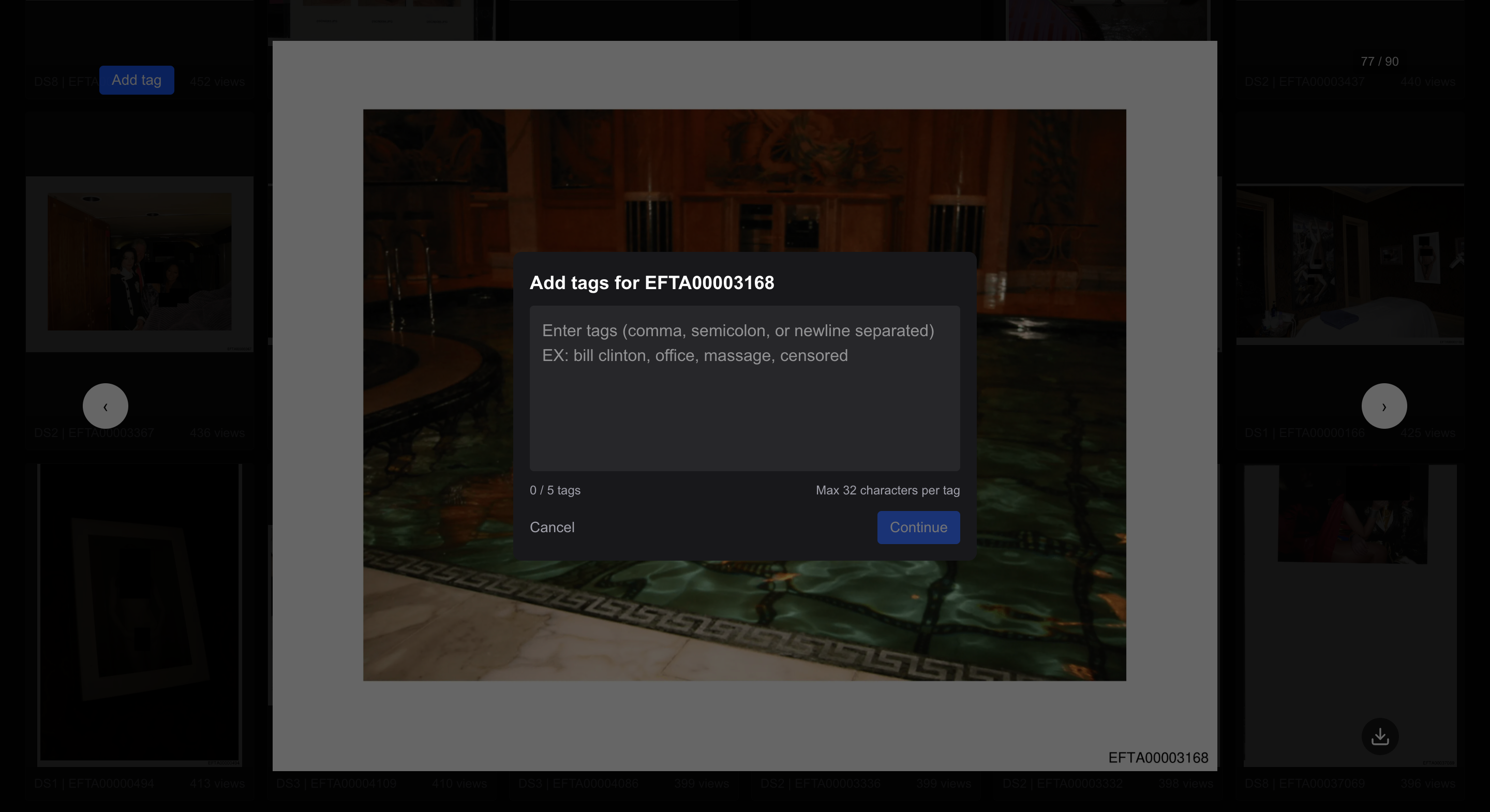
Community tagging feature to add context and metadata for searchable images.
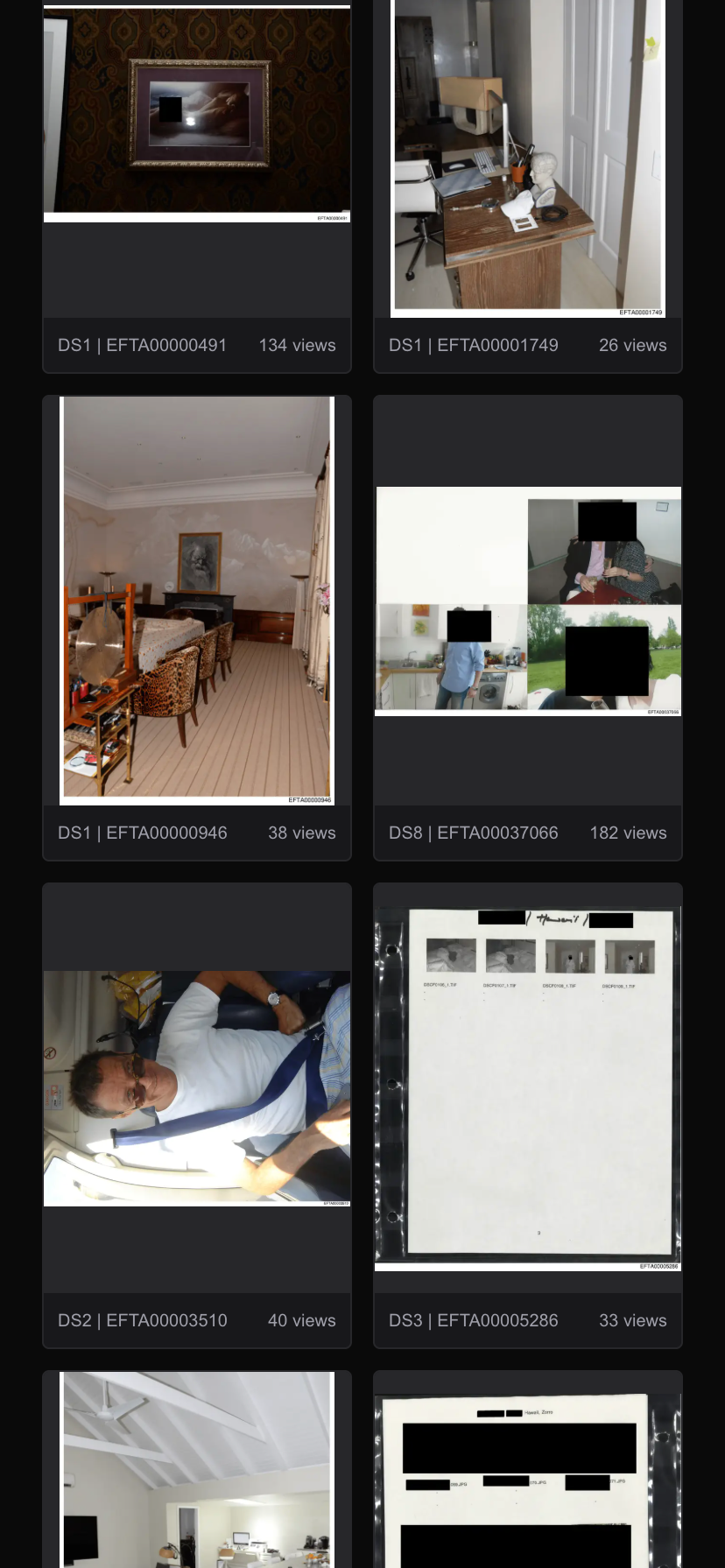
Mobile-friendly design with swipe navigation in modal view.
EpsteinLibrary.org started as a response to a frustrating user experience, but it has grown into an ongoing experiment in making large, uncomfortable datasets more accessible. The project continues to evolve based on community feedback, with a focus on performance, usability, and transparency. My goal is to keep improving the tooling around it while staying mindful of the responsibility that comes with presenting sensitive public records.